Дерево каталога для DIY-магазина
stroy-s.org →
С помощью ML проанализировали каталог крупного ритейлера (NDA) и пересобрали навигацию под реальные пользовательские сценарии. Результат: конверсия добавления в корзину выросла с 0,8% до 2,1%, доля сессий без взаимодействия с каталогом сократилась на 27%. А выручка выросла на 198% — без увеличения бюджетов на рекламу.

Когда 99% теплого трафика уходит с сайта ни с чем
Крупный российский ритейлер (NDA) столкнулся с проблемой: при высоком трафике и миллионных вложениях в его привлечение конверсия из каталога в корзину держалась на уровне 0,8%. Пользователи активно ходили по сайту, просматривали товары, но до корзины доходили единицы.
Основной канал продаж — онлайн-магазин с более чем 5 000 заказов в день. Каталог огромный, категорий и подкатегорий — сотни. В такой структуре пользователь терялся, делал много лишних кликов и уходил ни с чем.
Задача — сделать путь к покупке проще и быстрее.
0,8% — это плохо?
Прежде чем что-то менять, важно понять: а действительно ли текущая конверсия низкая? Может быть, для этой ниши и такого ассортимента это нормально? Чтобы не действовать вслепую, мы провели исследование.
У нас есть своя база данных по eсom-проектам: от fashion и электроники до крупных маркетплейсов и нишевых магазинов. Мы проанализировали метрики у сопоставимых игроков: в той же товарной категории, с похожим объемом трафика и структурой каталога.
Результат: да, 0,8% — это действительно ниже средней планки для ниши клиента. У конкурентов с похожими условиями средняя конверсия из каталога в корзину держится на уровне 1,5-3%. То есть речь шла не просто о субъективном ощущении клиента — проблема была реальной и подтверждалась цифрами.
Собираем и анализируем данные
Прежде чем перестраивать каталог или внедрять ML, мы собираем и изучаем данные: историю заказов, сезонность, сохраненные товары, поведение разных групп пользователей. Источники данных предоставляет заказчик — а мы их обрабатываем и структурируем. Информация может быть в разных системах — в Яндекс.Метрика, Amplitude, CMS, CRM, ERP, учетная система. Мы умеем агрегировать это в единую базу: подключаемся, выгружаем, чистим и подготавливаем к работе.
Важно: данные должны быть внутри компании. Мы не используем внешние источники, чтобы избежать погрешностей.
Что мы выяснили в ходе анализа
Начнем с того, что каталог магазина представлял собой избыточно разветвленную структуру с множеством уровней вложенности: категории, подкатегории, под-подкатегории и так далее.
В результате пользователь: тратил в среднем 5-7 кликов, чтобы добраться до нужного товара. А также терялся в навигации, пропускал важные разделы или вовсе уходил с сайта.
Яркий пример, выявленный в ходе кастдева: одна из категорий магазина содержала до 5 уровней вложенностей. В результате 8 из 10 пользователей путались в структуре и не понимали, куда идти, чтобы найти необходимое.
Перегруженные VS пустые категории — что хуже?
Часть категорий содержали более 300 SKU, что приводило к эффекту «парадокса выбора»: пользователь терялся среди большого ассортимента, поэтому вероятность выбора снижалась. Другие категории были практически пустыми — содержали менее 5 товаров или вовсе отсутствовали на складе. Это вызывало отток.
Важно: переизбыток выбора мешает покупке не меньше, чем его отсутствие: в первом случае пользователь устает выбирать, во втором — уходит, не увидев вариантов.
Товар есть, но его не найти
Даже если нужный товар был в наличии, найти его в каталоге было сложно. Категории были названы технически или неочевидно, некоторые товары относились к нескольким категориям, но были размещены только в одной. Кроме того, пользователю часто приходилось перепробовать 2-3 ветки, чтобы найти нужное.
В некоторых случаях нужный товар вообще не отображался — либо из-за нулевых остатков, либо из-за неочевидной логики размещения.
Что говорили цифры
На момент начала проекта ключевые метрики выглядели так:
— конверсия из каталога в корзину — 0,8%;
— конверсия из корзины в оплату — 60%;
— средний чек в пределах среднего по рынку.
Это значит, что только один из 125 пользователей, просматривающих каталог, в итоге добавлял что-то в корзину. Остальные просто уходили — не потому что товар им не нужен, а потому что не могли его найти или запутывались в структуре каталога. Так бизнес недополучал значительную часть потенциальной выручки.
Гипотезы, с которых началась трансформация каталога
На основе анализа данных и поведенческих паттернов мы сформулировали несколько гипотез, которые легли в основу улучшений.
— Товары приобретаются покупают «комплектами» под конкретные сценарии. Около 12% пользователей регулярно собирают наборы под конкретную задачу — это может быть подготовка к определенному событию, ситуации или цели. А значит, что товары должны быть сгруппированы не только по категориям, но и по цели использования.
— Новички мыслят задачами, а не категориями. Примерно 30% новых пользователей ищут товары не по названиям разделов, а по жизненным ситуациям: например, «для дома, «в поездку» и тому подобное. Классическая структура каталога для них не работает.
— Сложная структура отпугивает слабомотивированных. Пользователи с низкой вовлеченностью теряются в древовидной навигации, делают до 10 лишних кликов и уходят, так и не добравшись до корзины.
Эти гипотезы стали основой для следующего этапа — архитектурной переработки каталога и внедрения персонализированного ранжирования.
Решение: интеллектуальная реорганизация каталога с помощью МL
Универсальный каталог был одинаков для всех. Но пользователи приходят с разными задачами — кто-то хочет купить сезонный продукт, кто-то подбирает продукт для конкретного занятия, а кто-то просто смотрит, что появилось нового. К тому же, поведение меняется быстро: человек может искать одно, а через пару минут перейти к совсем другой категории.
В таких условиях каталог просто не может быть статичным. В теории можно было бы настроить каталог вручную: собрать редакторов, разбить пользователей на сегменты и показать каждому сегменту то, что им потенциально нужно.
Но на практике сценариев поведения гораздо больше, чем этих самых сегментов. Охватить их вручную невозможно, а если и попытаться — то это займет месяцы и все равно приведет к усредненному результату. Поэтому мы использовали машинное обучение (ML), чтобы подстроить каталог под реальные сценарии поведения. На основе прошлых действий, интересов и запросов система подсказывает, какие категории и товары наиболее актуальны именно этому человеку.
Цифровые профили пользователей и товаров
Персонализация каталога начинается со сбора данных о поведении пользователей: что они смотрят, какие категории чаще открывают, сколько времени проводят на страницах товаров. Система учитывает даже косвенные признаки — например, сезонность спроса или тип устройства, с которого заходят покупатели — и упаковывает все это в цифровой профиль поведения.

На следующем этапе пользователей объединяют в группы со схожими интересами. Это не условное деление на «мужчин 25–30 лет» и «женщин 30-45 лет» а динамические кластеры, которые алгоритмы формируют на основе реальных действий: один сегмент может отражать схожие привычки и образ жизни, другой — устойчивую привязанность к определенному продукту.
Чтобы объединять похожих покупателей в группы, мы тестировали разные методы. Для базовых задач применялись k-means и c-means, для более тонкой сегментации — методы поиска ближайших соседей (ANN search). Иногда мы использовали PCA, чтобы уменьшить размерность данных и выделить наиболее информативные признаки.
Важно, что границы между этими группами не фиксированы: система постоянно уточняет их в ходе A/B-тестов, оставляя только те варианты сегментации, которые увеличивают конверсию. Аналогичный подход используется и к товарам: каждый из них получает свой цифровой «отпечаток», в который входят текстовое описание, характеристики и даже визуальные признаки — форма, цвет, упаковка. Когда у алгоритма есть «отпечатки» и пользователей, и товаров, он может сопоставить их и определить, что стоит показать конкретному человеку.
Три подхода к генерации каталога
После мы собрали первую модель ранжирования, которая переставляла товары внутри категорий так, чтобы наверху человек видел именно то, что ближе его поведению и интересам. А это, в свою очередь, резко увеличивало шансы на добавление товара в корзину.
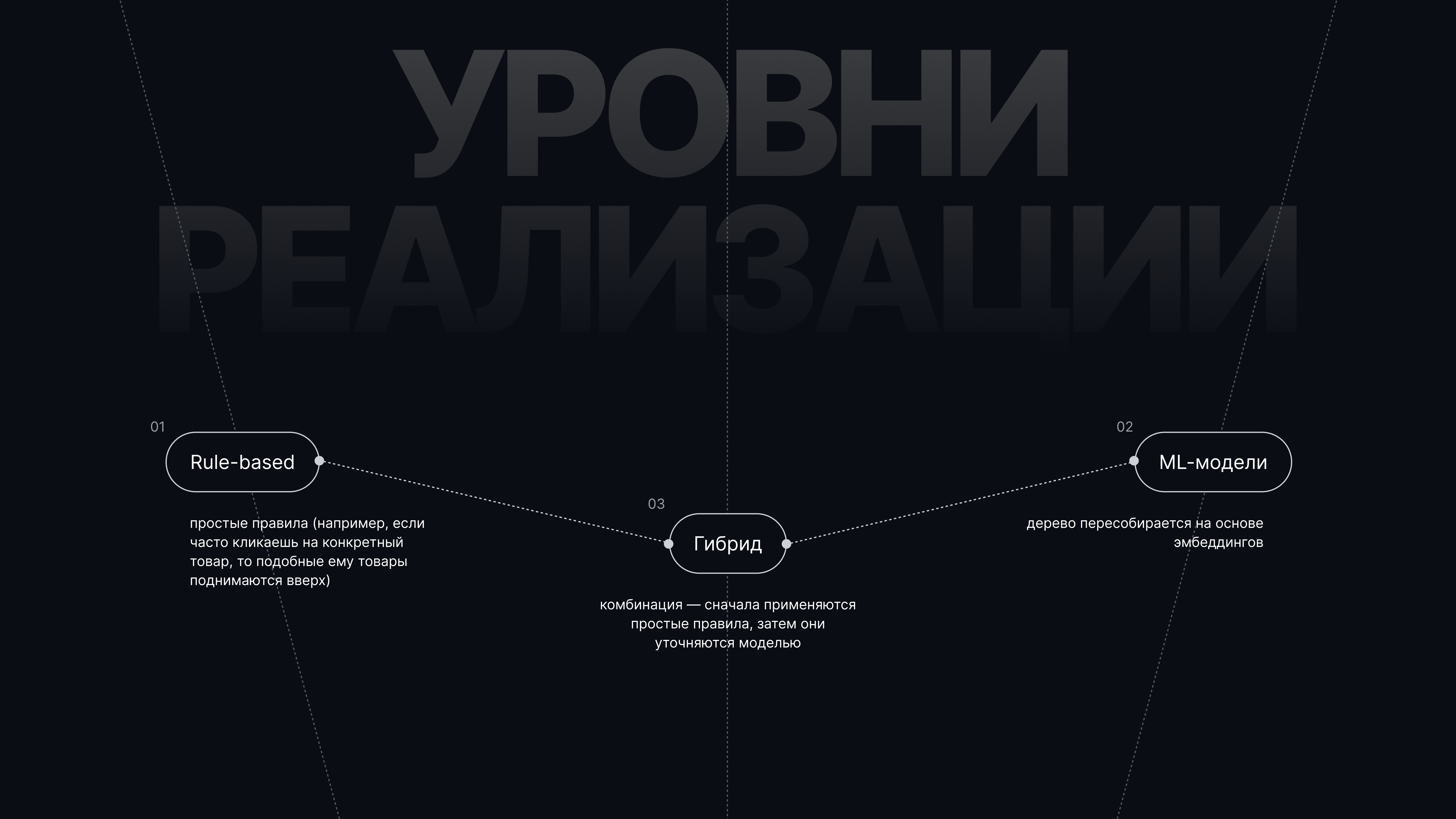
Здесь возможны три уровня реализации:
— Rule-based: простые правила (например, если часто кликаешь на конкретный товар, то подобные ему товары поднимаются вверх);
— ML-модели: дерево пересобирается на основе эмбеддингов;
— Гибрид: комбинация — сначала применяются простые правила, затем они уточняются моделью.
Как уже говорили, структура формируется не по стандартной иерархии, а под конкретные задачи пользователя. Она может дополнительно адаптироваться под частотные поисковые запросы, повторяющиеся покупки, поведение в блоках рекомендаций, комбо-сценарии.
Динамическое ранжирование категорий
Помимо персонализации внутри разделов мы реализовали персонализацию на уровне самого дерева. Алгоритм анализировал, какие категории интересны конкретному пользователю или сегменту, и соответствующим образом перестраивал порядок их отображения. Для постоянных покупателей определенного вида товаров нужные категории поднимались вверх. Менее релевантные — опускались.

Сокращение глубины и упрощение пути к товару
После алгоритм убрал категории, где товаров либо совсем не было, либо была всего пара позиций. А избыточные и дробные подкатегории объединил в более понятные блоки. Это позволило сократить глубину дерева и упростить навигацию: пользователю больше не нужно было перескакивать между разными ветками, чтобы найти связанные между собой товары.
Вместе с тем структура стала динамичной: если в разделе временно нет товаров, он скрывается из каталога. Это помогает избежать ложных ожиданий.
Временные категории и автоматические подборки
Помимо основной структуры система стала создавать временные категории. Это происходит тогда, когда алгоритм замечает устойчивые паттерны совместных покупок. Например, пользователи часто кладут в корзину одни и те же товары одновременно.
В таких случаях формируются автоматические подборки — «живые» блоки, которых изначально не было в каталоге. Они подстраиваются под поведение аудитории и появляются только тогда, когда действительно востребованы.
Примеры таких подборок: «Набор в дорогу», «Для новичков», «Популярно этим летом».
Главная ценность этих временных категорий в том, что они сокращают путь до покупки. Пользователь видит готовый набор, который решает задачу целиком, и может добавить несколько товаров сразу — без долгого поиска по разным разделам. Это упрощает путь к покупке и особенно выручает тех, кто сам еще не знает, что именно ищет.
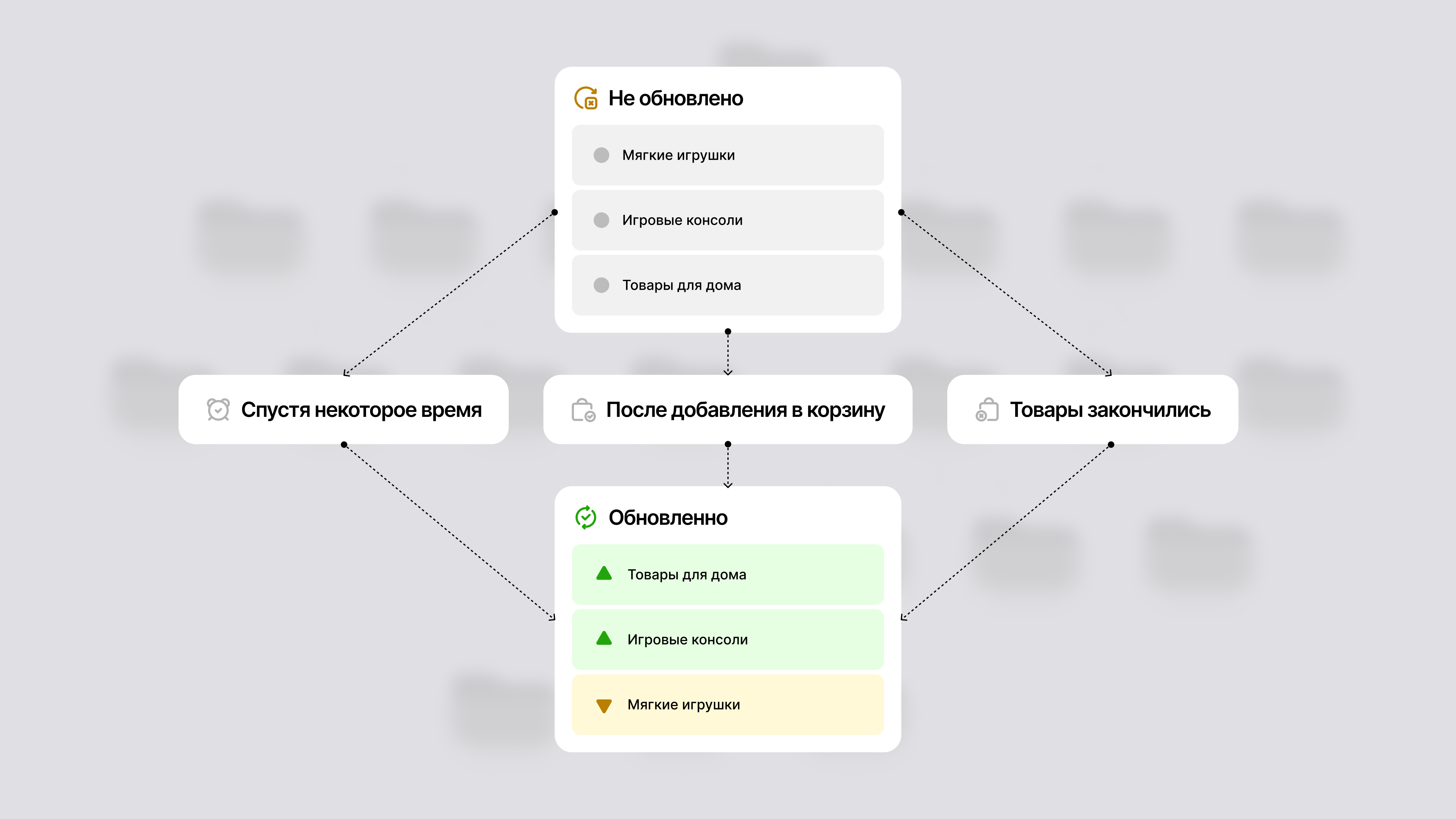
Обновление дерева
Обновление персонализированного дерева может происходить по-разному. В некоторых случаях достаточно батчевого режима — раз в сутки или несколько раз в день.
В других требуется перестройка в реальном времени: дерево меняется сразу после действий пользователя или после того, как товары в категории закончились (или их стало слишком много). Такой подход дает максимальную персонализацию, но требует больше ресурсов.
Иногда используется комбинированная модель: верхний уровень дерева — приоритетные категории — обновляется моментально, а остальная структура — по расписанию.
Как подбираются модели
На этапе обучения наши специалисты Data Science тестируют разные комбинации эмбеддингов и методов кластеризации.
Цель — найти такую конфигурацию, которая даст стабильный прирост нужных метрик: выручки, конверсии, глубины просмотра, сокращения сессий, в которых пользователи не взаимодействуют с каталогом. Когда подход подтверждает эффективность, он закрепляется и применяется для всех новых пользователей.
Каждое изменение — будь то логика дерева, подборки или сортировка товаров — проходит A/B-тестирование. Мы сравниваем версии между собой, измеряем влияние на бизнес-результаты и оставляем только те, что дают реальный прирост.
Главный итог проекта — выручка выросла в 2,3 раза
После внедрения новой структуры каталога и персонализированной логики показа, выручка выросла значительно — при том же объеме трафика онлайн-магазин получил:
— десятки тысяч дополнительных заказов в месяц;
— почти 100 млн дополнительной выручки в месяц;
— +198% прирост к выручке.
Иначе говоря, бизнес стал зарабатывать больше просто за счет того, что пользователям стало легче находить нужные товары. Улучшение навигации, умное ранжирование и адаптация под поведение дали хороший прирост без дополнительных вложений в маркетинг.
Приятный побочный эффект: конверсия из корзины в оплату также выросла. Почему?
Раньше пользователи чаще бросали корзину — не потому что передумали, а потому что путь к покупке был утомительным: много лишних действий, мало уверенности в выборе, неочевидная навигация. Теперь пользователь быстрее находит нужное — без десятков лишних кликов и попыток. Каталог подстраивается под его поведение: предлагает товары, которые актуальны здесь и сейчас. И в корзину попадают не случайные позиции «на потом», а то, что человек действительно собирается купить.
Вместо выводов
Такой подход особенно оправдан, когда у проекта стабильный поток заказов (от 1 000 в день) и есть накопленная пользовательская история. В этих условиях ML-модели работают максимально точно: понимают поведение без ручной настройки и заранее подсказывают, что может заинтересовать.
По мере роста трафика и ассортимента система не усложняется — наоборот, становится точнее. Чем больше данных, тем лучше она адаптируется к поведению реальных пользователей.
А что будет дальше?
Проект можно масштабировать вглубь — персонализируя не только каталог, но и другие точки взаимодействия. Главная страница и спецпредложения могут адаптироваться под сезонность, поведение и интересы конкретного пользователя. Вместо универсальных блоков — точечные подборки.
Следующий шаг — автоматическое формирование товарных комплектов под задачу. Например, «Набор для летнего бега» или «Экипировка для новичка в зале». Такие комбо-наборы сокращают путь до покупки и повышают средний чек.
Дополнительно ML можно внедрить и на финальном этапе — в корзине. Алгоритмы будут подсказывать сопутствующие товары, основываясь на паттернах поведения и контексте выбора, а не на случайных связках.
Стек технологий
1C
1C Битрикс
PHP
Python
JS
Сотрудники
Юлия Пшеничная
Менеджер проектовАлександр Баландин
ДизайнерПересвет Колтырин
Frontend-разработчикОлег Лазовский
PHP-разработчикЗайнуддин Муталибов
Backend-разработчикАнтон Шиян
ТестировщикДенис Гетман
Backend-разработчикДмитрий Гребенщиков
PHP-разработчик